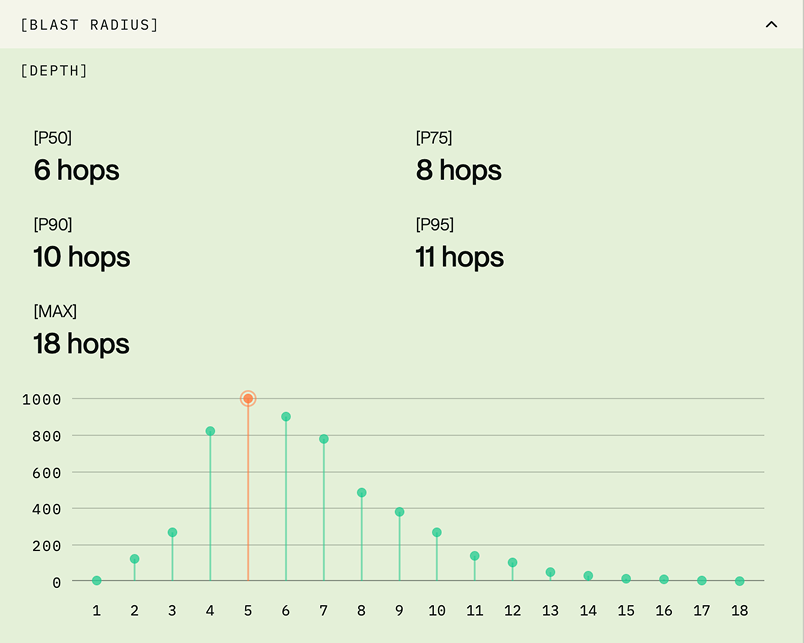
.png)
.png)
.png)
.png)
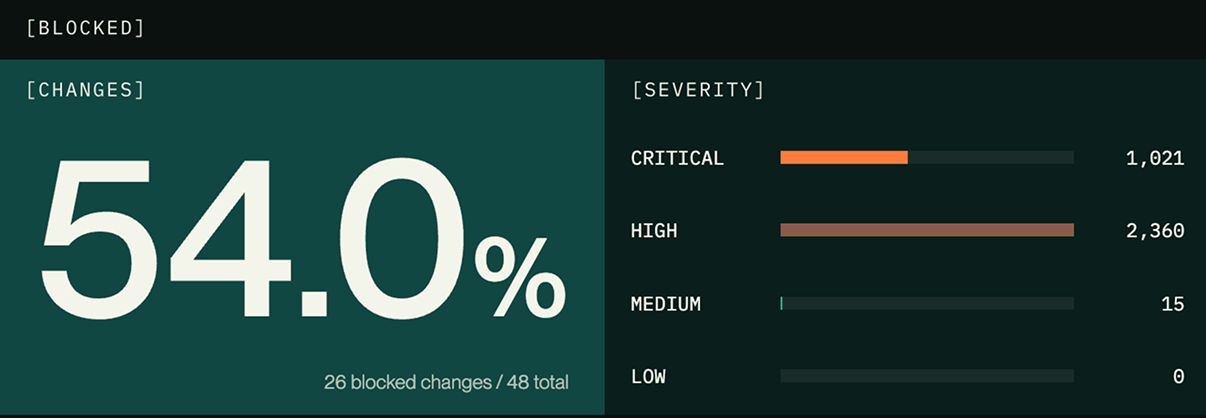
Outages often start as small changes.
A configuration tweak. A dependency update. A routine deploy.
By the time the problem shows up, it is already too late.
Teams lose hours tracing failures they did not expect. Evenings, weekends, and life moments disappear into incident response.
Most outages begin with a routine change.
Most teams only see the impact after production.
Stag prevents these incidents at the source. Before deployment.